For a brief moment last spring the disruptions caused by COVID-19 appeared to offer a once-in-a-lifetime teachable moment in the form of an opportunity for real-time discussions with stakeholders about the concepts and assumptions that are at the heart of equating state assessments. Alas, much like people’s understanding of equating, that opportunity proved to be illusory. As spring 2020 state assessments were cancelled, so too was the unique equating challenge they presented. Yes, if and when state assessments return there will be formidable equating challenges as described by Michelle Boyer and Leslie Keng in a recent blog post and paper. None of those challenges, however, will recreate the straightforward, textbook case that would have existed if students were tested in spring 2020.
The Spring 2020 Scenario
When school buildings across the country closed last March, states and schools were at various points in their instruction and assessment cycles. States with school years ending in mid-June had completed approximately two-thirds of their 2019-2020 school calendar. Spring testing in some content areas was still six to eight weeks away in some of those states.
It is accepted as fact that instruction and student learning in the spring were negatively affected by the suboptimal conditions that existed after school buildings closed. Remote schooling was implemented hastily, to varying degrees, in the midst of a pandemic, and with different guidance or underlying philosophies (e.g., stay the course with the curriculum, focus on high priority targets, don’t introduce anything new). If state assessments had been administered at the end of the 2019-2020 school year it is safe to assume that statewide student performance on content introduced after March would have been a) worse than on similar content in previous years and b) relatively worse than on content introduced earlier in the school year. That performance combination would have resulted, at a minimum, in some highly instructive conversations between states and their assessment contractors and in some cases a deeper understanding of equating.
Equating – A Quick Review of What we Expect to See
The figure below contains scatterplots that show the type of relationship we might have expected to see on a 15-item anchor test – a set of common items administered in 2019 and 2020 under normal pre-COVID conditions. The plot in the upper left corner shows no change in performance from 2019 to 2020. The plot on the upper right shows improvement from 2019 to 2020 and the plot on the lower right shows a decline in performance from 2019 to 2020.

The plots are simplified using percent correct instead of IRT item parameters and depict very uniform changes, but they are illustrative of what we might expect to see in a normal year.
Equating 2020 – Anything But Normal
If state assessments had been administered in spring 2020, it is likely that we would not have seen the uniform changes shown in the plots above. Instead, if state performance in 2020 had been “on track” to be unchanged from 2019 (upper left plot), we may have seen something like the plot below. In this plot, performance from 2019 to 2020 is unchanged on items covering content introduced in the first two trimesters prior to COVID-19 disruptions, but there is a 6-12 percentage point drop on the five items covering content introduced in the third trimester.
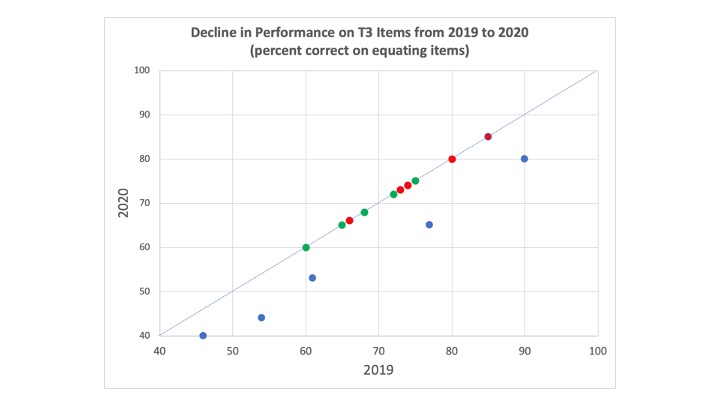
When all is said and done, overall state performance would have been lower in 2020 than 2019; and that is a result that would not be unexpected given the events of spring 2020.
But, wait…
What if predetermined equating rules had kicked in and kicked out those five T3 items from the anchor set because they behaved differently than the other common items. With performance differences that large, it is certainly plausible that all of the T3 items would be dropped from equating. The resulting anchor test used for equating, therefore, would contain 10 items covering content introduced in the first two trimesters (i.e., prior to COVID-19 and remote learning).
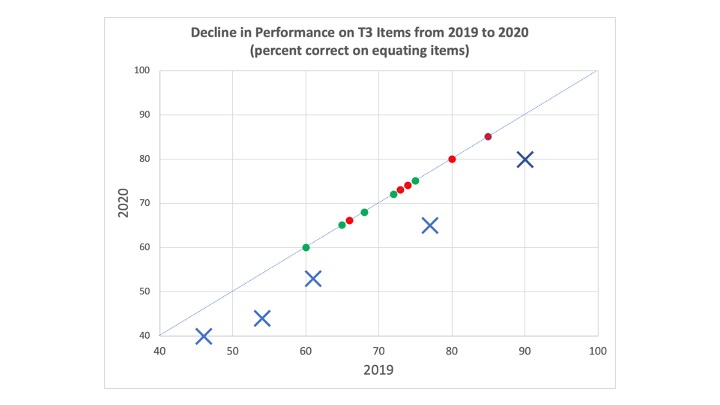
With the five T3 items dropped from equating, the likely outcome is that there would have been little or no change in statewide performance from 2019 to 2020. That is a result that might be regarded as “fair” and an accurate reflection of the underlying proficiency of the 2019 and 2020 classes of students.
Like the man with two watches
Like the proverbial man with two watches, a state assessment director with one set of equating results knows how performance changed from last year to this year, show her two sets of equating results and she’s not quite sure. Which set of results is valid, accurate, true?
I can tell you from personal experience that one of the quickest ways to piss off a state policymaker or district administrator is to tell them that when it comes to equating, there is no truth. That being said, when it comes to equating, there is no truth.
There are, however, lots of assumptions that are built into equating. There are assumptions about the standards, the test blueprint, the items, the test administration and scoring, the anchor test and equating methodology, the students tested, and the instruction that those students have received. The upshot of all of those assumptions is that 95% (perhaps more) of the equating process occurs before the test to be equated is even administered. The outcome of the equating process is determined based on those assumptions much more than on the set of technical analyses that we tend to call equating. (And no, I am not arguing that mistakes made during those analyses will not affect equating results – been there, done that.)
If the state assessments had been administered in spring 2020, it would have been clear that many of the assumptions built into the process had not been met. When evaluating the two sets of results shown above, it would have been relatively easy to engage policymakers in discussions about those assumptions and the claims that could be supported by each set of results. On the basis of those discussion, policymakers would have been able to make an informed decision about whether to adopt the equating approach that showed a decline in performance, the approach that showed no change, or perhaps both, or perhaps neither. Most importantly, the policymaker would have been in a strong position to communicate those results so that they could be interpreted and used appropriately.
In spring 2021, those conversations will be just as important, but the situation will not be nearly as straightforward. For example, students taking the 6th grade mathematics test will have missed instruction on some portion of the 5th grade curriculum as well as likely having much more variable 6th grade experiences than would be assumed in a “normal” school year, more variable even than in 2020 with its single statewide disruption to in-person schooling.
The Art and “Science” of Equating
In a 1987 Applied Psychological Measurement article, Linda Cook and Nancy Petersen wrote,
Many psychometricians view score equating as a subjective art with theoretical foundations because the true relationship between scores on different forms of the same test is never known in practice.
As the stakes associated with K-12 large-scale assessment increased over the past three decades we have attempted to strengthen the equating process by applying those theoretical foundations and latest research. Factors such as the choice of equating models, design of the anchor test, test design, and sampling of students have been the focus of extensive research. We have also tried to position equating as more of an “objective science” than a “subjective art” by establishing a priori rules for the inclusion/exclusion of items from equating. Such rules may make the process more objective by eliminating the inclination and opportunity to cherry-pick equating solutions that produce the most desirable results. The rules may also support the critical scientific principles of reproducibility and replication. On the whole, however, there may be a net negative in going too far to portray equating an objective, technical process. As scientists, we cannot privilege replication at the expense of the scientific principle of falsifiability and the need to validate assumptions.
All psychometricians understand the truth in the adage that equating processes work best when they are not necessary; and for decades the field did everything in its power to minimize the need for equating; or put another way, we designed testing situations to require as little as possible from the equating process. In the past two decades, however, changes to K-12 assessment have significantly outpaced our ability to fully explore and understand their effects on equating.
The adoption of more complex learning standards, the introduction of new item types including extended response and writing tasks, relaxed timing constraints within test sessions, expanded test windows, through-course testing, enhanced accommodations and universally available tools, computer-based testing, CAT, licensed test content, and a return to a reliance on item banks for test development are a few of the changes that individually, let alone in combination with each other, have made the equating process more challenging and increased the need to make the evaluation of assumptions a critical part of each and every equating activity. Unfortunately, there is little time and few resources available to conduct such evaluations and we are often at a loss to explain unexpected equating results.
If large-scale K-12 assessment returns in spring 2021, the need to proceed cautiously with equating will be obvious. In many ways, however, that need will not be any greater than it has been for several years.

You must be logged in to post a comment.