
I have to confess that I fell down a rabbit hole while writing my blog post this week.
My original plan was to comment on a Hechinger Report article published late last month, Standardized tests in their current format are ‘incredibly antiquated, with the gripping subtitle, ‘Some experts suggest using this moment to change the way testing is done’.
The article caught the attention of several in my social media network, with one colleague commenting
Shaking my head….
Are we still having this debate? Is this not the biggest click-baity thing you can write in the testing world?
The preliminary title of my planned post was “Antiquated Objections Yield Antiquated Solutions to Antiquated Tests” because after taking the bait and reading the article, as my good friend suggested above, my biggest takeaway was I’ve heard this all before – over and over again. All of the favorite objections were there
“The costs and time associated with assessments, delayed results, and failure of tests alone to improve students’ academic results leave many to wonder if they are worth the effort.”
“Don’t provide much useful information on whether students are learning to think critically and creatively”
The article even included the obligatory “unique perspective on testing” from the former elementary school teacher turned K-12 education research assistant.
And, of course, following the reporting handbook to the letter, the article opened with a quote from a noted scholar to put everything about large-scale standardized testing in “proper perspective”:
“We’re leaving this awful world for our kids and grandkids, where the temperatures are going up, the illnesses are spreading, the hurricanes are getting worse, the water is disappearing,” he said. “And we’re worried about multiple choice tests on trivial information.”
In this case, the quote was from Robert Sternberg, whom the article initially described as a “frustrated. Really frustrated” professor of psychology at Cornell University. (I get it. Everyone I’ve known who spends a lot of time at Cornell ends up frustrated, really frustrated. Sorry, old Ivy League inside joke.)
In the next paragraph, however, Sternberg was also described as a psychometrician.
Ah, that word. You’ve got my attention.
I don’t know whether it was the reporter’s choice to label Sternberg a psychometrician, jut something pulled from his Wikipedia page, or if he self-identifies as such.
When I think of psychometricians – or at least those involved in the K-12 large-scale testing part of psychometrics – Sternberg’s name doesn’t usually come to mind.
But that’s the thing about psychometrics, it’s a broad umbrella that covers a lot of people and fields. Although you would think that crowded under the same umbrella, there would be a lot more crosstalk and collaboration.
I just had to know a little bit more, so I jumped onto the Semantic Scholar website to review Sternberg’s list of recent publications and that’s when I fell into the rabbit hole. My first impression was man, this dude loves triangles, but then I noticed the little ‘author scorecard’ in the upper left corner of the page.
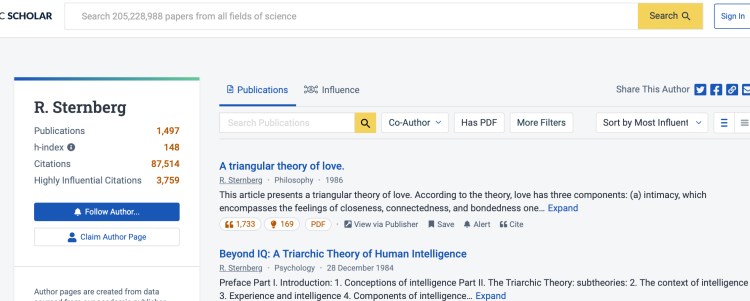
Nearly 1,500 publications, 90,000 citations – 3,800 of which were classified as ‘highly influential citations. Impressive. And then there was the ‘h-index’ score of 148.
Like most assessment people and sports fans, I am a sucker for any statistic or metric. Not being personally involved in the publications game, I was not familiar with the h-index. Sure, I have heard my academic friends at NEERO and my daughter (a budding academic) talk about such metrics. But my psychometric friends in NCME and NERA, not so much.
I have never given such metrics much thought, but I have more time on my hands now.
Perhaps, I thought, this ‘h-index’ has some merit. Similar to IRT, it seems to put people and journals on the same scale. We all like that.
Would the ‘h-index’ have been helpful to me in deciding which sessions to attend if I had travelled to San Diego for the AERA and NCME conferences this year? I don’t think that h-index includes entertainment value and showpersonship, but impact on the field is important, too, when selecting a session.
I did a quick Google search to help me interpret Sternberg’s h-index score of 148. The first article I read told me that for a researcher in the field for a couple of decades, a score above 20 would be good. A score of 40, really good, 60 would be great. OK, a higher number is better. 148 sounds really, really good.
The second article told me that ‘h-index’ might already be antiquated itself – too influenced by longevity (like some baseball HOF statistics) and older publication patterns. It didn’t account well for things now valued, like collaboration.
And another research study told me there was quite a lot of variation in h-index by field. Yeah, all of us who took tests to get into graduate schools of education are familiar with variation by field.
So, I started to plug in the names of some of the legends and leaders in educational assessment and measurement – current and former – as well as other people whose work I know and respect.
This seemed to be working fairly well.
People like Messick, Cronbach, Linn, Hambleton, Mislevy, and Pellegrino had h-index scores in the 50s, as did Stan Demo and Lee Shulman. Lorrie Shepard was hovering nearby at 48.
Sue Brookhart, Barbara Plake, Mark Wilson, Eva Baker, Ed Haertel, Randy Bennett, and George Madaus had scores in the 30s.
Suzanne Lane, Dan Koretz, Henry Braun, Audrey Amrein-Beardsley, Derek Briggs, and Andrew Ho had scores in the 20s.
Kolen and Brennan at 32 and 40, respectively, forever linked.
Greg Cizek and Steve Sireci were both in the 30s. Not sure if that’s valid.
John Hattie and Marilyn Cochran-Smith had h-index scores in the 60s.
Eric Hanushek – 83. Scary, but explains a lot (pun intended).
Linda Darling Hammond was at 104 and Ray Pecheone at 13. That works.
Within the Fuchs family, Lynn had a 105 and Doug a 93. Probably makes for some interesting conversations around the dinner table.
And my h-index score was 4. Same as my daughter’s as she finished graduate school this spring. Sounds about right.
H-index. I see the value. I see the shortcomings. It has a nice beat and I can dance to it. I’ll give it a 77.
Psychometrician, Measure Thyself!
In a recent post, I mentioned the need for new, advanced metrics to measure outcomes like school effectiveness and student achievement, and in my last post I talked about all of the new inputs on the table which will also need metrics and indicators.
But what about the tests that we produce and the individuals, teams, and organizations that produce them. Shouldn’t there be some type of rating scale for them as well.
We have never been really good at coming up with metrics to describe the quality of our tests.
Even communicating effectively about seemingly simple things like reliability and standard errors has eluded us.
Andrew Ho recently posted a Tweet calling for a ban on validity coefficients. I didn’t bother to dig into the details, but that seems like a solid recommendation whatever the context.
Attempts to describe alignment, both simple (Webb) and complex (Surveys of Enacted Curriculum) have left users wanting more (or less).
And don’t get me started on the spate of rating systems based on documents like the CCSSO Criteria for Procuring and Evaluating High-Quality Assessments.
But this is about so much more than the technical quality of a test.
There must be some type of accurate, useful, and informative way to measure and describe the validity and utility of a large-scale testing program, its effectiveness, its ability to do what it was designed to do (yeah, I tried to sneak that last one by you).
Quantitative. Qualitative. Everything is on the table.
Federal peer review? Nope, still not asking the right questions.
Buros or those old Achieve evaluations of state assessments? Closer, but not quite.
Damn. You would think that we would be better at this.
Here’s the problem.
The thing is, turns out it’s a lot easier to measure whether something is doing what it’s supposed to do when you actually had to think about and define what it’s supposed to do as you were designing and implementing it.
Shocking, right. (And yes, the fact that this same general principle applies to both test instruments and testing programs has confused the hell out of far too many psyshometricians, but we’ll save that discussion for another day.)
For the most part, however, large-scale K-12 testing has meant never having to question why; and like love, never having to say you’re sorry.
My award-winning friends at the Center for Assessment have been pushing tirelessly for the design and use of large-scale assessment programs to be driven by a Theory of Action. (They claim to know what they mean by TOA and they probably do. They use lots of arrows.)
Decades of federally-mandated state testing, however, have made asking for justification about why an assessment program is being administered or why it is designed the way it is a Sisyphean struggle.
Why? Because.
If not now, when. If not us, well, then somebody else.
But as “some experts” suggest (e.g., those referenced in the subtitle of the Hechinger Report article), perhaps this is the moment to start asking “why” again.
The key question then is whether there is anybody left in large-scale testing who is ready to answer the “Why?” questions about testing programs.
Given that we stopped asking “why” about large-scale tests so long ago, there’s no guarantee that there is.
My guess is those people are out there, but we might not find them in the places we usually look.
And they might not look like the people we usually find.
But, they are out there.
And it’s certainly worth doing whatever it takes to find them.
Otherwise, we’ll have to go to the econometric folks for answers. And nobody wants that.
Image by David Mark from Pixabay

You must be logged in to post a comment.